Character encoding in .per
The character encoding used to edit and compile .per form specification files is defined by the current locale.
Form elements (typically, labels) can be written with non-ASCII characters of the current character encoding used in development.
In a GRID container,
the form element positions and sizes are determined by counting the width of characters, rather than
the number of characters, or the number of bytes to encode the characters. This rule is important
when using a multibyte character encoding such as BIG5 or UTF-8. However, it can be ignored when
using a single-byte character encoding such as ISO-8859-1 or CP-1252, where each character has width
of 1 and codepoint of 1 byte.
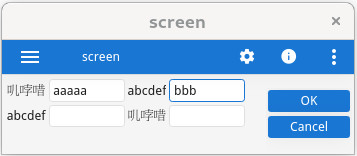
For example, in the UTF-8 multibyte character encoding, a Chinese character is encoded with three bytes, while the visual width of the character is twice the size of a Latin character.
In the next example, these 3 Chinese characters 叽 哱 唶 have the same width as the labels using six Latin characters. As a result, all the labels will get the same size (6 cells), and all fields will be aligned properly when using a monospace or proportional font display: