Understanding locale settings
This is an introduction to application locale definition.
It is critical to understand how the different components of a program handle locale settings. Each component (i.e. runtime system, database server, database client software, front-end, and terminal emulator) have to be configured properly to get the correct character set conversions through the whole chain. The chain starts on the end-user workstation with front-end windows and ends in the database storage files.
Figure 1 shows the different components of a Genero Business Development Language process.
The yellow rectangles show where locale configuration parameters have to be set:
- The source files are encoded in a given character set. When compiling sources
(fglcomp, fglform), the compilers use the OS locale
(LANG/LC_ALL) to encode the resulting program files (.42m,
.42f). For more details, see Defining the application locale.Important: When compiling, make sure that the LANG/LC_ALL environment variables match the encoding of the source files.
- At runtime (fglrun), the OS locale (LANG/LC_ALL) for the runtime system must match the code set
of the program files (.42m, .42f). For more details, see
Defining the application locale.Important: At runtime, make sure that the LANG/LC_ALL environment variables match the encoding of the program files.
- The locale of the database client must match the locale of the runtime system. Each database
vendor uses it's own locale configuration system. For more details, see Database client settings.Important: At runtime, make sure that the database client locale matches the application locale (i.e. LANG/LC_ALL).
- The locale of the database server defines the encoding for data on the server side. This encoding can be different from the database client locale (one can for example store the data in UTF-8, while client programs use ISO-8859-15), but it is usually the same character set. See database vendor documentation for more details.
- When using the TUI mode, the terminal emulator must be configured with the character set corresponding to the application locale (2).
- (C): Both ends may use a different character encoding, but the conversion is done automatically.
- (M): Both ends must use the same character encoding, because no conversion is done.
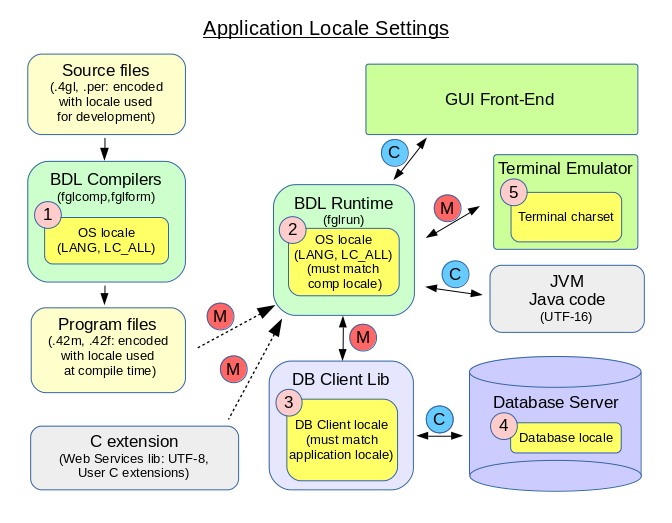
The typical mistake is to forget to set the runtime system locale (LANG/LC_ALL), or the database client software locale.
A character string is just a set of bytes; The same code might represent different characters in
different code sets. Therefore, systems cannot detect that the current locale is correct, and won't
raise any error, except when a set of bytes does not represent a valid code point in the current
codeset. For example, the Latin letter é with acute (UNICODE: U+00E9) will be
encoded as 0xE9/233 in CP1252, but in CP437 it will be encoded with 0x82/130. The codes 233 or 130
are valid characters in both code sets. If the database uses CP1252, 233 will represent an
é and 130 will represent a curved quote. If the client application uses CP437, the
é will be encoded as 130, stored as a curved quote, then fetched from the database
as is and displayed back as é in the CP437 code page. As result, the end user
cannot see that the character stored in the database is actually wrong, until another properly
configured DB client application queries the database.
It is also important to identify database server character set (in other words what code set characters are stored in the database). Usually the database character set is defined when creating a database entity.
The best way to test if the characters inserted in the database are correct is to use the database vendor SQL interpreter and select rows inserted from a BDL program. The rows most hold non-ASCII data to check if the code of the characters is correct. Some databases support the ASCII() or better, the UNICODE() SQL function to check the code of a character. Use such function to determine the value of a character in the database field. If the character code does not correspond to the expected value in the character set of the database server, there is a configuration mistake somewhere.
If you run a BDL application in TUI mode (or a batch program doing DISPLAYs), you must properly configure the code set in the terminal window (X11 xterm, Windows® CMD, putty, etc). If the terminal code set does not match the runtime system locale, you will get invalid characters displayed on the screen. On Windows platforms, the OEM code page of the CMD window can be queried/changed with the chcp command. On a Gnome terminal, go to the menu "Terminal" - "Set Character Encoding".