It is critical to understand how the different components of a program handle locale settings. Each component (i.e. runtime system, database client software, front-end, terminal) has to be configured properly to get the correct character set conversions through the whole chain. The chain starts on the end-user workstation with front-end windows and ends in the database storage files.
Figure 1 shows the different components of a Genero Business Development Language process.
- The red rectangles show where character set conversion occurs. Conversion can happen in the front-end side, for C-based Web Services extension and in the database client. No conversion is done by the fglrun runtime system.
- In the runtime system (fglrun), the locale and code set support is based on the POSIX C runtime libraries driven by the setlocale() standard function. This locale setting is defined by the LC_ALL (or LANG) environment variable. The locale of the runtime system must match the code set of the deployed program modules (42m and 42f files).
- The terminal (for TUI applications) and the C runtime library are represented in magenta rectangles. These elements will use the locale of the runtime system.
- The locale of the database client must match the locale of the runtime system. Each database vendor uses it's own locale configuration system.
- The database server uses it's own locale settings, which can be
different from the runtime system / db client locale. You can for
example store the data in UTF-8 but have programs using ISO-8859-1.
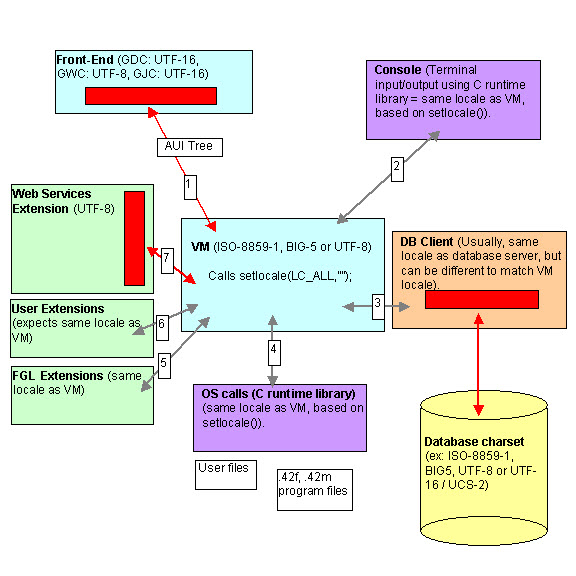
Figure 1. The Locale Settings schema
The typical mistake is to forget to set the runtime system locale (LANG/LC_ALL), or the database client software locale. Systems cannot detect that the current locale is appropriate and don't raise any error, except when a set of bytes does not represent a valid code point in the current codeset. A character string is just a set of bytes; The same code might represent different characters in different code sets. For example, the Latin letter é with acute (UNICODE: U+00E9) will be encoded as 0xE9/233 in CP1252 but will get the code 0x82/130 in CP437. The codes 233 or 130 are valid characters in both code sets, so if the database uses CP1252, 233 will represent an é and 130 will represent a curved quote. If the client application used CP437, the é will be encoded as 130, stored as curved quotes but are retrieved from the database as is and displayed back as é in the CP437 code page. From the front-end side, you can't see that the character in the database in wrong.
Pay attention that on recent UNIX™ systems, the default locale is set to UTF-8. If your application has been developed on an older system, it is probably using a single-byte character set like ISO-8859-1 or CP1252, and program need to be executed in this locale, not in the UTF-8 locale.
It is also important to identify database server character set (i.e. in what code set the characters are stored in the database). Usually the database character set is defined when creating a database entity.
The best way to test if the characters inserted in the database are correct is to use the database vendor SQL interpreter and select rows inserted from a BDL program. The rows most hold non-ASCII data to check if the code of the characters is correct. Some databases support the ASCII() or better, the UNICODE() SQL function to check the code of a character. Use such function to determine the value of a character in the database field. If the character code does not correspond to the expected value in the character set of the database server, there is a configuration mistake somewhere.
If you run a BDL application in TUI mode (or a batch program doing DISPLAYs), you must properly configure the code set in the terminal window (X11 xterm, Windows™ CMD, putty, etc). If the terminal code set does not match the runtime system locale, you will get invalid characters displayed on the screen. On Windows platforms, the OEM code page of the CMD window can be queried/changed with the chcp command. On a Gnome terminal, go to the menu "Terminal" - "Set Character Encoding".